借助义元改善词表示学习

摘要
义元是语义上的最小单位,单词的每一个含义通常都是很多义元组合而成的。为了让每个词义的义元更加确切,人们进行了手工标注,并构建了常识性的语言知识库。这篇文章指出,单词的义元信息可以改善词表示学习(一种将单词映射到低维语义空间的技术,是许多NLP任务的一个基本步骤)。关键点在于利用义元信息准确捕捉单词在特定语境下的确切含义。具体说来,作者拓展了skip-gram框架,提出了三种义元编码模型来学习sememes-senses-words的表示,而且在不同的语境中确定词义时用到了注意力机制。为了检验学到的词表示的质量,进行了两个实验,包括相似度计算和单词类推,结果新模型的效果显著好于设置的基础模型。这也说明了作者的模型可以对义元信息正确建模,通过注意力机制使义元作用于词表示学习。
引言
义元是最小的语义单元,现有概念(比如某个词的词义)都可以通过一个有限集合内的义元组合而来。问题在于,某个词的义元并不明确,于是人们人工构建了一个常识性的语言知识库。
HowNet就是这样的一个知识库,里面的每一个概念都用和它相关的一个或多个义元进行了标注。与WordNet不同,HowNet强调由义元表示的part和attribute的意义,在单词相似度计算、语义分析方面被广泛使用。
作者的目标在于将义元信息纳入词表示学习,从而得到改进的词嵌入。WRL是许多NLP任务,包括语言建模、神经机器翻译,基本的、非常重要的步骤。
关于词表示的研究已经有很多,其中word2vec实现了效率和有效性非常不错的平衡。在word2vec中,一个词对应一个词嵌入,忽略了词的多义。(Huang et al,2012)提出一种处理WRL的多原型模型,根据上下文聚类进行无监督的词义归纳和词嵌入。(Chen et al,2014)进一步利用WordNet同义词集指导词表示学习。
从上得出结论:词义消歧在词表示学习中非常关键。作者认为每个单词下的义元标注可以带来必需的语义上的调整。为探讨其可行性,提出了SE-WRL模型,该模型可以在检测词义的同时,学习词表示。具体说来,这个框架把每个单词的词义看作是义元的组合,根据上下文迭代地进行词义消歧,通过拓展skip-gram模型学习sememes-senses-words的表示。该框架提出一种基于注意力的方法来自动根据上下文选择近似的词义。
实验中用两个任务评估模型,包括词语相似度和词语类比,最后举几个例子。结果表明该模型结果显著好于其它模型,尤其在单词类比方面。这说明该模型在义元信息的帮助下可以构建更好的知识表示,在词义消歧方面还有潜力。
本文贡献总结如下:
- 第一个利用知网义元改善词表示学习的工作(as far as)
- 借助知网的义元信息,根据上下文,成功利用注意力机制检测词义、学习词表示
- 大量实验证明有效性
相关工作
词表示
词义消歧和表示学习
系统方法
本节介绍SE-WRL框架。具体来说,我们在经过语义正则化的大型语料库上学习模型,得到义元、词义、词嵌入。
下面首先介绍知网、词语结构。接着介绍常规的WRL模型skip-gram。最后详细介绍三种义元编码模型。
Sememes,Senses and Words in HowNet
知网中标注了每个词的精确词义,对于每一个词义,其重要的部分、属性都以义元的形式给出。
义元之间形成了复杂的层次结构,本文没有考虑这种结构,把义元视为一个集合。
约束:W-S-X (word-sense-sememe)C(w):上下文集合
常规skip-gram模型
该模型认为词嵌入应该和其上下文词语相关;
给定目标词,最大限度地提高上下文词语的预测概率;
利用一个滑动窗口选择上下文词语;
对于词序列H={w1,…,wn},skip-gram模型的目的是最大化:
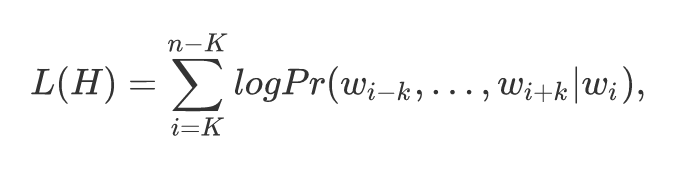
经softmax归一化:
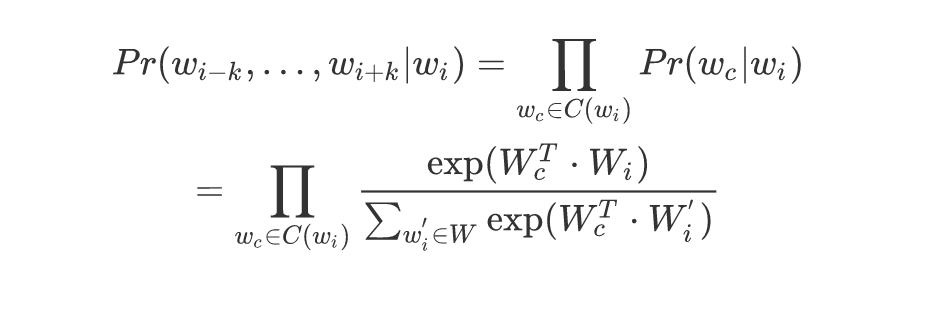
SE-WRL Model
SSA
简单聚合模型。一个词嵌入,由组成它的义元向量取均值得到。m为词语w的义元总数。
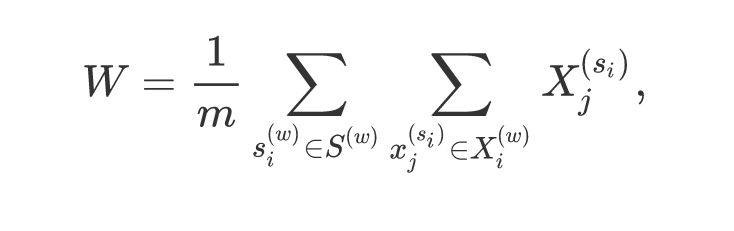
包含相同义元的相似词语可能会最终形成相似的表示。
SAC
SSA模型不足:每一个词只有一个表示
利用attention机制,自动根据目标词为上下文词选择合适的词义;通过对上下文词消歧,来学到更好的目标词表示。
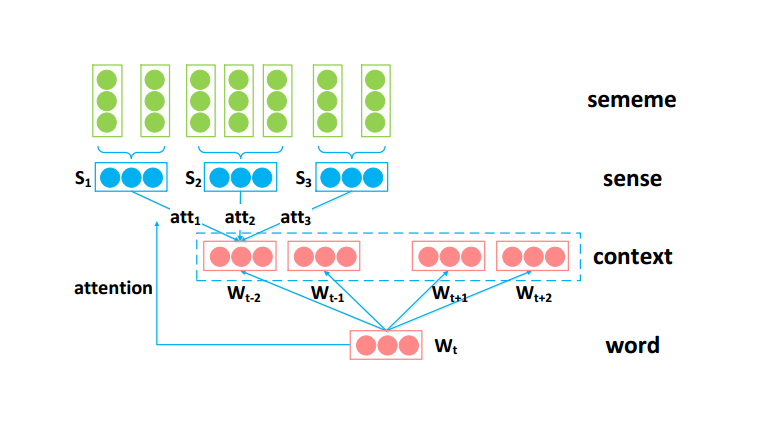
目标词(as an attention):original word embedding
上下文词:sememe embeddings,公式为:
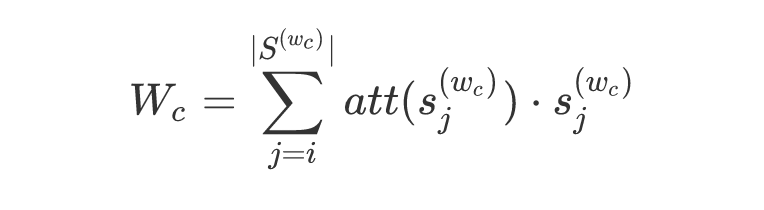
意思是:每个sense embedding*attention score,然后求和.
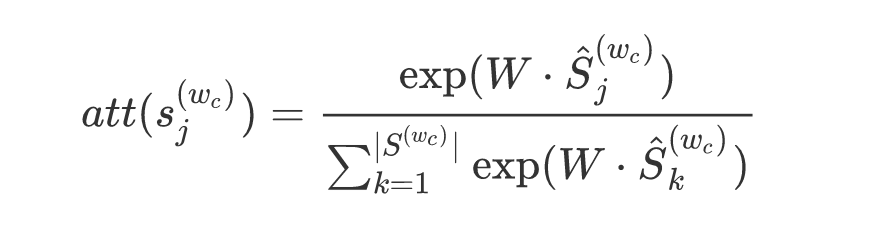
每一个sense由组成它的sememe embeddings取均值得到:
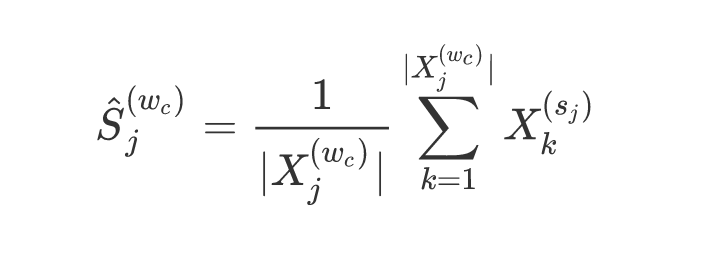
attention机制认为,上下文词的sense embedding和目标词w越相关,在构建上下文词的word embedding时这个sense就越该被考虑。这种机制下,上下文中的每个词都表示成了其sense的特定分布。
SAT
和SAC相反,SAT将很多的上下文词视为attention,来选择目标词的词义。
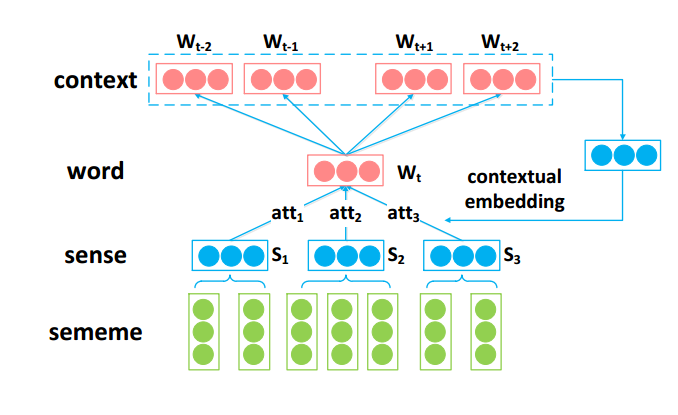
上下文词(as an attention):original word embeddings
目标词:sememe embedding,公式:
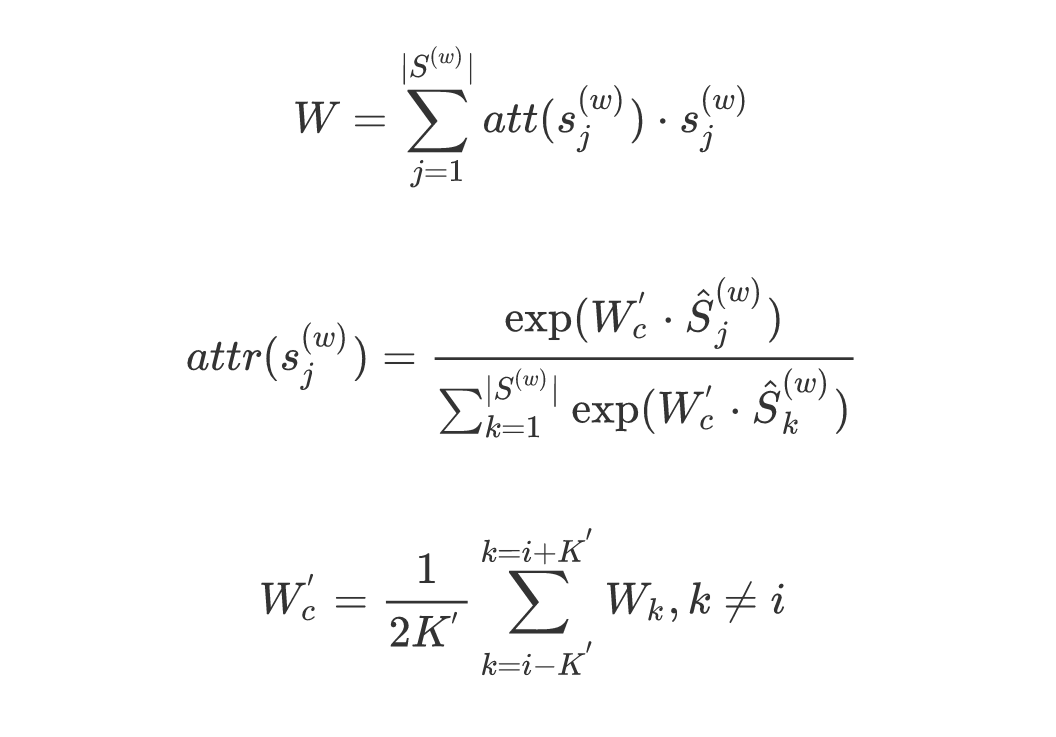
直觉上,SAT效果应该好于SAC。
总结展望(我的-0-)
文章提出一个模型,该模型可以对义元信息较好地建模,改善了词表示.在词语类推和相似度计算中,相比传统模型该模型都展示出了优势.
在处理义元时忽略掉了其复杂的层次结构,并且只对中文进行处理.可以想象的是,如果对层次结构有较好的建模,词表示会更加精确,其表示的学习过程也会更加容易收敛.另外,这种机制应该适用于其它语言,值得尝试.