linear and logistic regression in TensorFlow
Linear Regression
问题定义:
设X为生育率,Y为预期寿命,能否找到一个线性函数f使得Y = f(X)?
数据集描述:
名称: Birth rate - life expectancy in 2010
X = 生育率. Type: float.
Y = 预期寿命. Type: foat.
数据量: 190
数据形式: (X,Y)
方法1:
假设X和Y之间的关系是线性的,这意味着有w和b,满足:Y_pred = wX + b.
本例中w,b都是scalar,
1 | w = tf.get_variable('weights',initializer=tf.constant(0.0)) |
损失函数使用均方误差
1 | Y_pred = w*X+b |
完整代码:
1 | import tensorflow as tf |
结论:
经过100次训练后,平均损失为30.04,w = -6.07,b = 84.93。
这证实了我们的假设,即出生率与一个国家人口的预期寿命之间存在负相关关系。 但是,这并不意味着多一个孩子会减少6年的寿命。
方法2:
假设X和Y满足:Y_pred = wX^2 + uX + b
只需修改部分代码:
1 | # Step 3: 创建变量,初始化为0 |
由于平方损失会给离群点太多的权重,这里损失函数考虑使用Huber loss:
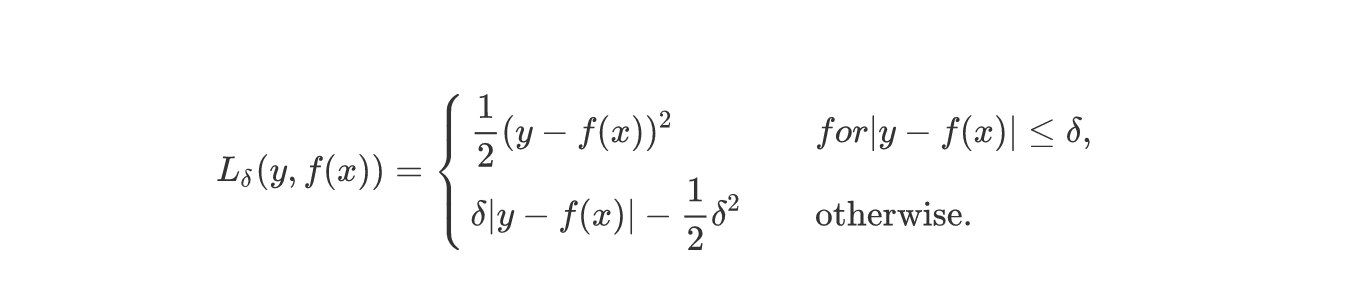
tensorflow提供了一些控制流操作:
1 | # 具体实现 |
最后结果为:w: -5.883589, b: 85.124306.
which one is better?
we do need test data set!!!
tf.data
使用placeholder和feed_dicts的好处是将数据处理与TensorFlow分离,使用python就可以轻松地shuffle, batch, generate arbitrary data. 不好的地方是,数据处理的线程很有可能是瓶颈,使整个程序slow down。
使用队列也是TF中处理数据的一个选项,队列允许pipelining、threading操作,减少了数据加载到placeholders的时间,但是难以使用且容易崩溃。
tf.data比placeholder更快,比队列更容易使用,而且不会crash。
数据存储在一个tf.data.Dataset对象中,而不是一个non-TensorFLow对象(numpy array)
tf.data基操:
创建DataSet
从tensor创建
1
2# features,labels都是tensors,也可以是numpy arrays
tf.data.DataSet.from_tensor_slice((features,labels))从file创建
1
2
3
4
5
6# 文件每一行代表一个数据,例如csv文件
tf.data.TextLineDataset(filenames)
# 每一个文件长度都固定,比如都是28*28的图片
tf.data.FixedLengthRecordDataset([file1,file2,file3,file4,...])
# tfrecord格式,(还没用过
tf.data.TFRecordDataset(filenames)
创建Iterator
取dataset中的数据需要用到迭代器
1
2
3
4
5
6# 只能遍历一遍
iterator = dataset.make_one_shot_iterator()
# 多次初始化,多次遍历
iterator = dataset.make_initializable_iterator()
# 返回一个或者一组样本
iterator.get_next()训练
1
2
3
4
5
6
7
8
9
10
11iterator = dataset.make_initializable_iterator()
...
for i in range(100):
# 每一个epoch都要初始化iterator
sess.run(iterator.initializer)
total_loss = 0
try:
while True:
sess.run([optimizer])
except tf.errors.OutOfRangeError:
pass
其它操作
1 | #简单的命令操作dataset |
Logistic Regression with MINIST
一个问题:
这个实验有多个数据集,训练集、验证集和测试集,如果每个数据集都有各自的iterator,那我们就得为每一个iterator创建一个graph。
不,可以用一个迭代器,用不同的数据初始化它
1 | iterator = tf.data.Iterator.from_structure(train_data.output_types, |
完整代码, tensorboard图示如下:
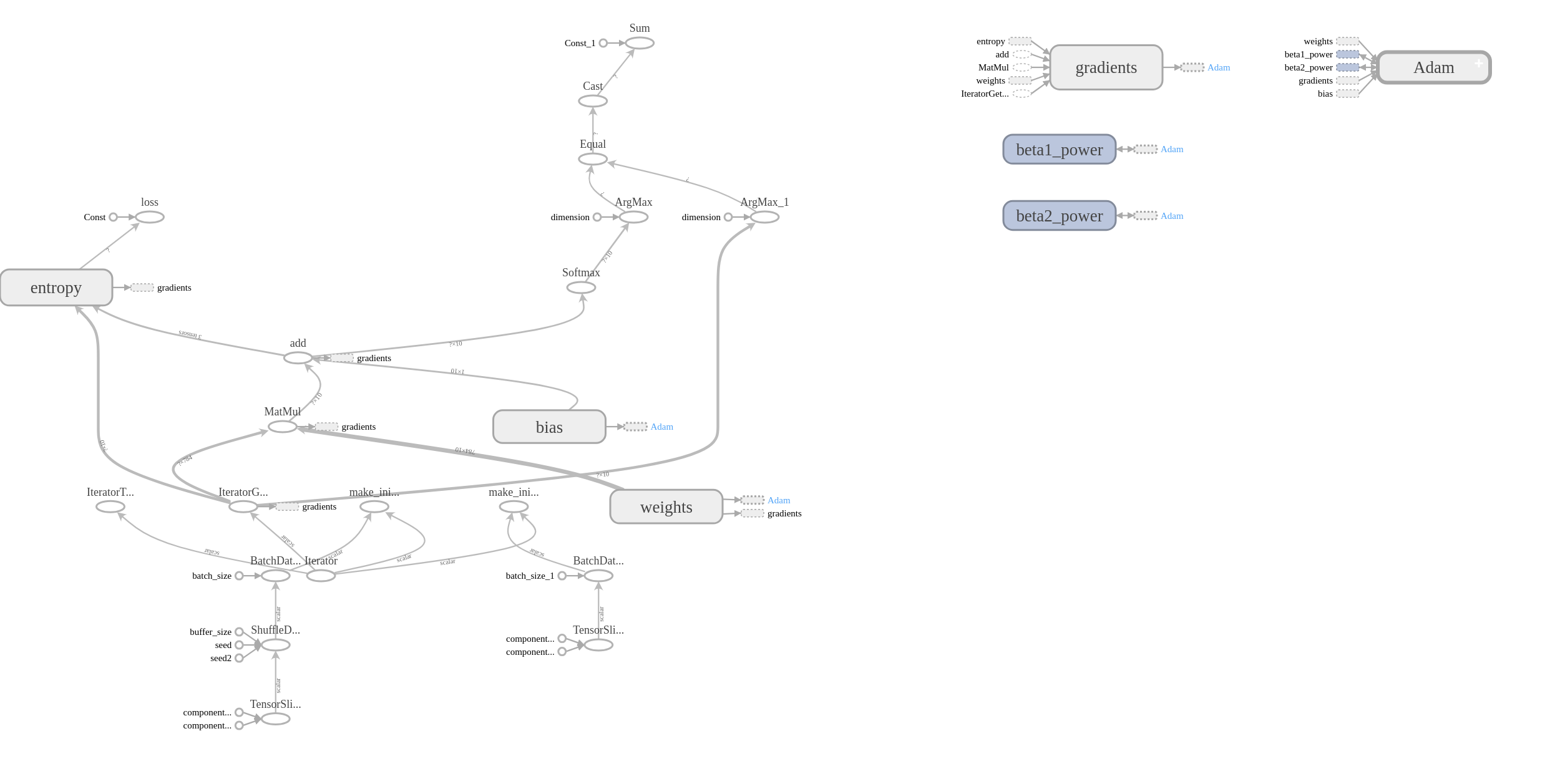
下一步,尝试将这个graph改造得有条理一些。